随机森林进行特征基因筛选
简介
随机生存森林通过训练大量生存树,以表决的形式,从个体树之中加权选举出最终的预测结果。构建随机生存森林的一般流程为:首先,模型通过“自助法”(Bootstrap)将原始数据以有放回的形式随机抽取样本,建立样本子集,并将每个样本中37%的数据作为袋外数据(Out-of-Bag Data)排除在外。其次,对每一个样本随机选择特征构建其对应的生存树。再次,利用Nelson-Aalen法估计随机生存森林模型的总累积风险。最后,使用袋外数据计算模型准确度。
数据说明
输入:数据包括3+N列:第1列是样品,第2列是生存时间,第3列是生存状态(0:生,1:死),第4+列为基因表达。
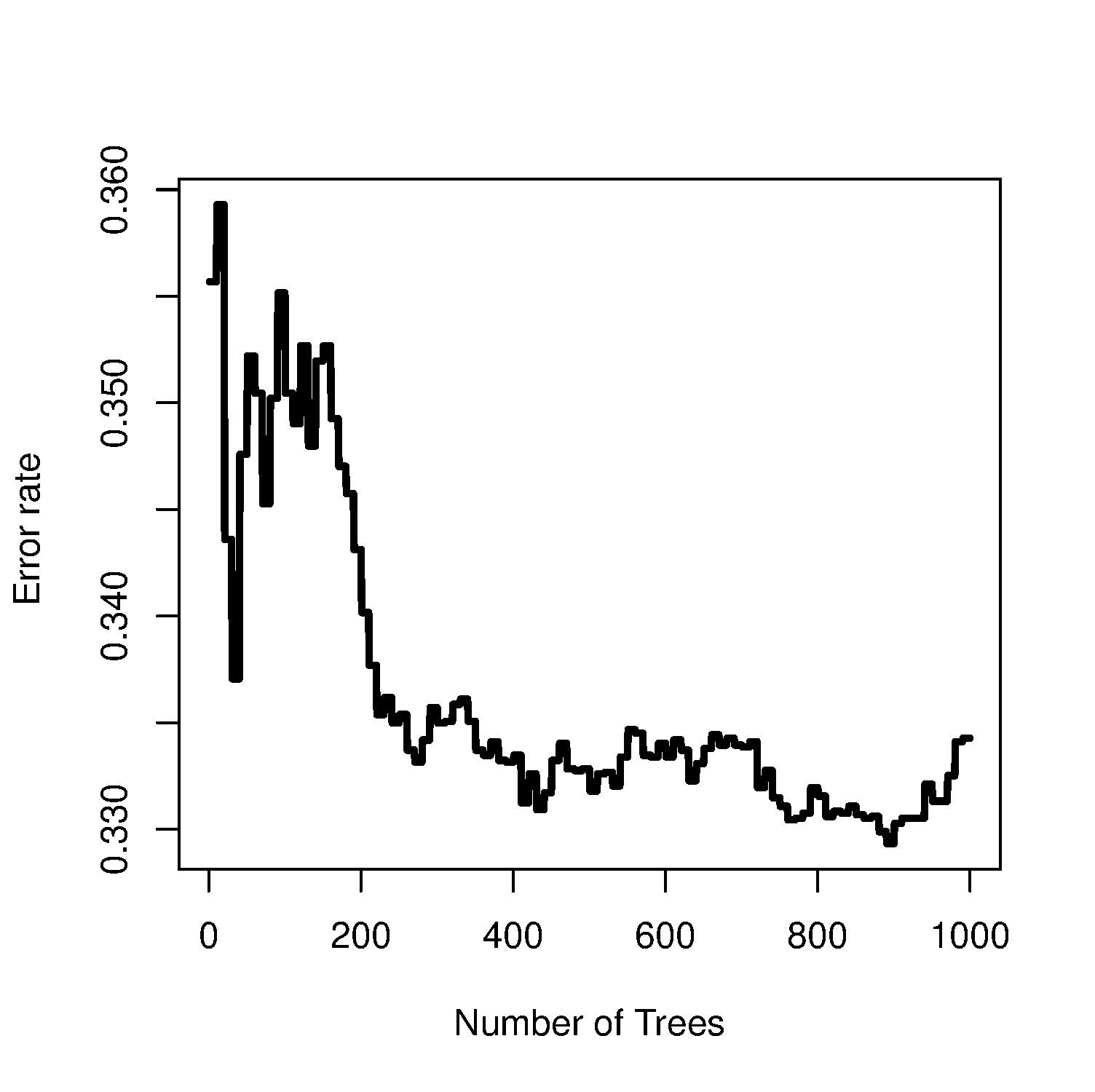
输出:不同生存树数量的模型预测错误率。VIP图。
论文例子
Fig 1.
如何引用?
建议直接写网址。助力10000+篇
(google学术),9000+篇
(知网)论文
正式引用:Tang D, Chen M, Huang X, Zhang G, Zeng L, Zhang G, Wu S, Wang Y.
SRplot: A free online platform for data visualization and graphing. PLoS One. 2023 Nov 9;18(11):e0294236. doi: 10.1371/journal.pone.0294236. PMID: 37943830.
方法章节:Heatmap was plotted by https://www.bioinformatics.com.cn (last accessed on May 4, 2026), an online platform for data analysis and visualization.
致谢章节:We thank Mingjie Chen (Shanghai NewCore Biotechnology Co., Ltd.) for providing data analysis and visualization support.